
Pickle it: How to Store a Python Object Across Files
Use this handy package to store python objects in your file system to be used in any script you like.
Introduction
Sometimes when coding, you may want to use an object that you created in a different program. In these cases, pickle is a great tool that you can use to gain some continuity between python scripts. To ‘pickle’ an object is to write, or ‘dump’, a python object into a file that you can store away and use again later. This object gets stored into a .pkl file and can be read, or ‘loaded’, in a separate program. This is a great way to collaborate with others that may be working on the same project as you. It is also particularly helpful in machine learning projects. Pickle is an excellent way to introduce a trained model from a different script into your current program in order to make predictions. In this post, I will show you how to use pickle, explain why I think it is useful, and give a couple of warnings as well.
How to pickle something
There are only a few simple steps to pickle an object and load it in another script.
- Specify the directory where you want your pickle file to go. This is where you name the .pkl file that you technically won’t have made yet. For example, if I wanted to name my new file ‘regression_model.pkl’, I would write that at the end of my file path. More on file paths below.
- Open the file with open(). Set mode to ‘wb’. This means you are writing a binary file.
- Store the object in that file with pickle.dump(). The first argument is the name of the object that you are dumping, the second argument is the file path to the new .pkl file you will be creating.

The steps to un-pickle a file are similar.
- Specify the file path of the .pkl file that you want to open.
- Open the file with open(). Set mode to ‘rb’, because you are reading a binary file.
- Use pickle.load() to assign the object to a new variable in the new script.
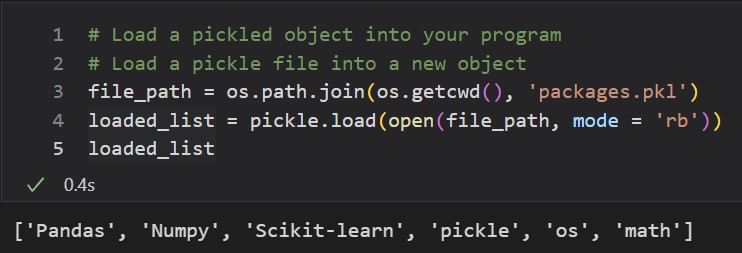
In both cases, you can also combine steps 2 and 3 into one line of code. This is shown in the second screenshot example. You will also see the use of certain os functions. os.path.join() is a way to combine filepaths. I like to use os.getcwd() to grab the current directory and use os.path.join() to append the desired filename to that home directory file path.
How pickle can help your machine learning projects
When you are creating a machine learning model, every time that will include training your model, testing its initial predictions, and using the model to make other predictions. Of course, you will need a trained model in order to make predictions. The issue is that you won’t want to train the model every single time you need to make predictions. You can guess where I am going with this. Pickle is a great way to introduce a trained model into a program built for making predictions. All you have to do is load the model in via pickle, and then you can easily make predictions on unseen data.
A word of caution
If you are familiar enough with Python to use pickle, you know how difficult Python can be when it comes to version control. Unfortunately, pickle can run into many issues if an object is dumped using one Python version and loaded in another, you could very easily run into some issues. Furthermore, there isn’t really a good way to check the contents of a pickle file before loading it, which means that if you are unsure where a pickled file comes from, there is a huge risk that you could be introducing something harmful onto your computer. For these reasons, I recommend loading pickle files that you yourself dumped and on the same machine. This is the best way to get as much functionality out of your pickle files without meeting any of the potential issues.
Conclusion
Adding pickle skills to your python toolset is a great step forward, especially if you are trying to pick up machine learning. With only a few commands needed, there is a lot of potential to help you optimize a process or project across many different python scripts. Try it today!